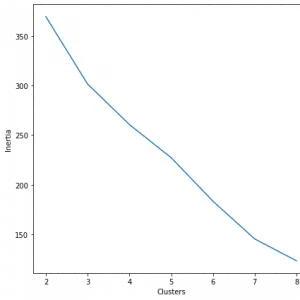
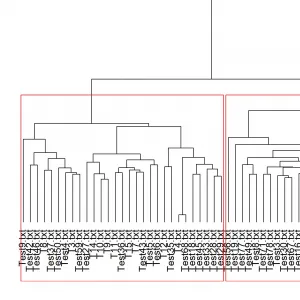
Dieser Artikel behandelt die Operationalisierung von Figurentypen im deutschsprachigen Drama. Ausgehend von der dramen- und theatergeschichtlichen Forschung werden Figuren bestimmt, die einem der drei Figurentypen ›Intrigant*in‹, ›tugendhafte Tochter‹ und ›zärtlicher Vater‹ entsprechen.
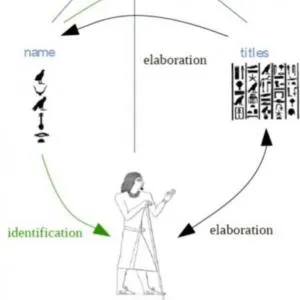
Der Beitrag beschreibt die Einführung einer neuen digitalen Methode zur Erforschung multimodaler grafischer Kommunikation für die Ägyptologie. Im Zentrum steht dabei der Aufbau eines digitalen Corpus, das Daten zur grafischen Kommunikation erfasst.
Der Beitrag widmet sich der digitalen Lücke im Kontext der Kunstgeschichte und Provenienzforschung und fragt nach Arten und Ursachen. Auf Basis einer Studie verschiedener Datenbanken und einer digitalen Methode werden Arten digitaler Lücken identifiziert und in einer (erweiterbaren) Typologie festgehalten.
Der vorliegende Artikel stellt ein Verfahren zur (teil-)automatisierten Analyse der Multimodalität von Webseiten vor. Dabei steht im Fokus, unbekannte Webseiten auf deren Multimodalität hin zu untersuchen, ohne dass diese vorher annotiert oder sonst anderweitig in Bezug auf ihre Multimodalität analysiert worden wären.
Technologien in den Digital Humanities bedürfen einer ethischen Untersuchung und Einordnung. Der Ansatz des Value Sensitive Designs ermöglicht einerseits, systematisch zu analysieren, welche Interessen und Werte in eine bestimmte Technologie eingeschrieben werden und ist zugleich ein Framework, um Technologien wertesensitiv zu entwickeln.
Durch die Öffnung und Digitalisierung des Peer-Review-Prozesses werden signifikante Verbesserungen in der Qualität geisteswissenschaftlicher Arbeiten möglich, dennoch wird Open Access of eine mangelnde Qualitätssicherung vorgeworfen.
Call for Papers
!! VERLÄNGERT BIS 15. MAI 2023 !!
Ziel des geplanten Sonderbands ist es, anhand verschiedener Zugänge und konkreter Fallbeispiele das Phänomen der nichteindeutigen literarischen Wertung unter den Vorzeichen der digitalen Transformation näher zu beleuchten.
This study aims at distinguishing comedies and tragedies among 112 dramas written by Calderón de la Barca, using procedures established by distributional semantics.
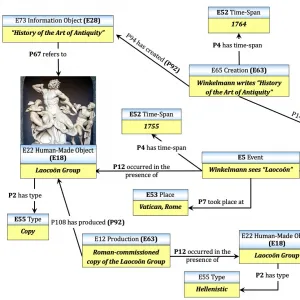
Der Beitrag versteht sich als Plädoyer für den interdisziplinären Austausch und eine vertiefte Diskussion über Methoden, Algorithmen und Linked Data Ansätze, denn Wissensgraphen und Netzwerkansätze kommen in ganz verschiedenen Disziplinen verstärkt zur Anwendung.