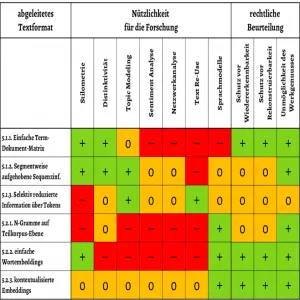
Das Text und Data Mining (TDM) mit urheberrechtlich geschützten Texten unterliegt trotz der TDM-Schranke (§ 60d UrhG) weiterhin Einschränkungen, die u. a. die Speicherung, Veröffentlichung und Nachnutzung der entstehenden Korpora betreffen und das volle Potenzial des TDM in den Digital Humanities ungenutzt lassen.
After a period of experimentation and prototyping, digital editions are considered a common standard and a serious, quite often even a better alternative to printed editions. In addition the TEI/XML provides a well introduced standard for mark-up of all relevant structural and semantic elements of an edition.
This article explores how digital methods, such as the analysis of Facebook page like networks, can complement ethnographic fieldwork, especially in cases of difficult access to a field. Drawing from anthropology, geography, and media studies, we present two case studies where ethnographic access is challenging.
Im Hinblick auf die Diskussion um den Status der Digital Humanities als wissenschaftliche Dizplin, zeigt der Artikel an einem konkreten Beispiel, wie im Zuge eines scalable reading die Diskussionen um Entsagung und Ironie in der Goetheforschung von Seiten der DH befördert und verbunden werden können.
Im vorliegenden Aufsatz werden die von den Digital Humanities ausgehenden Interventionen genutzt, um geistes-, mithin literaturwissenschaftliche Forschungspraktiken und ihre epistemischen Implikationen zu untersuchen.
Vergleichende Märchenforschung befasst sich mit dem Phänomen der erstaunlichen Nähe der Märchensujets in verschiedenen, sowohl räumlich als auch kulturell oft weit voneinander entfernten Volksgruppen.
Die Geistes- und Sozialwissenschaften befinden sich gegenwärtig innerhalb der Dynamik einer sich rapide digitalisierenden Gesellschaft vor zahlreichen neuen Herausforderungen. Wird von den Geistes- und Sozialwissenschaften gesprochen, schwingt die gewagte Grundannahme einer Kohärenz der darunter subsumierten Akteure und Aktivitäten mit.
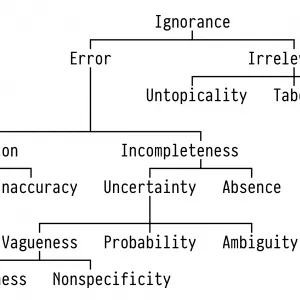
As the saying goes, »nothing can be said to be certain except death and taxes.« Uncertainty is an unavoidable aspect of life and thus we have an intuitive understanding of uncertainty, but coming up with a strict definition of uncertainty is hard.
Die Text Encoding Initiative (TEI) bietet bei der Transkription von Texten verschiedene Möglichkeiten, zweifelhafte Lesarten auszuzeichnen und diese sowie damit in Zusammenhang stehende Informationen umfangreich zu dokumentieren.
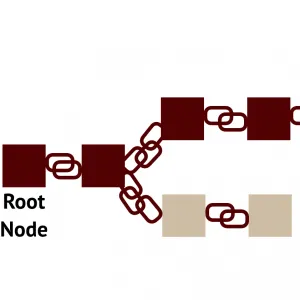
Blockchain sowie Bitcoin, die auf der Blockchain-Technologie basierende Kryptowährung, waren mit Sicherheit die meistdiskutierte Technologie 2017. Von der begeisterten Ausrufung einer »Revolution« bis hin zu kritischeren Tönen wurde eine weite Spanne von Positionen diskutiert.