Der Beitrag befasst sich mit der maschinellen Umsetzung und Schematisierung der universellen Struktur des Märchens. Dafür wird ein eigenes Markup-Schema zur standardisierten Kodierung des Inhalts verwendet. Vorgestellt wird u. a. ein digitaler Assistent für die semiautomatische Annotation des volkstümlichen Märchens.
Der Beitrag vollzieht die Entwicklung von Themenschwerpunkten und Stimmungsbildern zum Klimaschutz in österreichischen Zeitungen in einem Zeitraum von zwanzig Jahren mittels einer computergestützten quantitativen Datenanalyse unter Verwendung von Topic- und Sentiment-Analyse nach.
Die Autor*innen des Beitrags zeigen, exemplarisch an der Segmentierung, wie digitale Analysen Grundbegriffe der Sprach- und Literaturwissenschaft problematisch und damit deutlicher werden lassen.
Eine hypothesengeleitete literaturwissenschaftliche Fallstudie mit der Anwendung von Digital-Humanities-Verfahren. Primärtexte der Analyse sind dreizehn längere Erzähltexte des deutschsprachigen Gegenwartsautors Uwe Timm.
Die vorliegende Studie präsentiert und erprobt eine Methodik, mit der die Paratexte eines mittelgroßen Textkorpus erfasst und analysiert werden. Zunächst wird eine Einführung in die Erzähltheorie gegeben, dann werden die einzelnen methodischen Schritte zur Erfassung der unterschiedlichen paratextuellen und textuellen Signale ausführlich dargelegt.
This survey offers an overview of the existing body of research on sentiment and emotion analysis as applied to literature. The research under review deals with a variety of topics including tracking dramatic changes of a plot development, network analysis of a literary text, and understanding the emotionality of texts, among other topics.
Im Hinblick auf die Diskussion um den Status der Digital Humanities als wissenschaftliche Dizplin, zeigt der Artikel an einem konkreten Beispiel, wie im Zuge eines scalable reading die Diskussionen um Entsagung und Ironie in der Goetheforschung von Seiten der DH befördert und verbunden werden können.
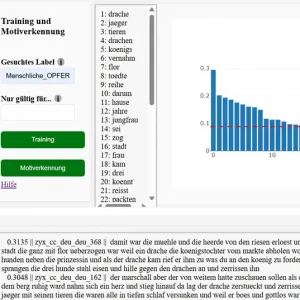
Vergleichende Märchenforschung befasst sich mit dem Phänomen der erstaunlichen Nähe der Märchensujets in verschiedenen, sowohl räumlich als auch kulturell oft weit voneinander entfernten Volksgruppen.
The Codex is a project that aims to achieve deep integration between text and structured data. Although data can be ›extracted‹ from texts and stored in a database – whether that data be persons or places referenced, events recounted, etc. – the non-sequential nature of databases can make it difficult to put the data back into context.
Digitale Analysen literarischer Gattungen gehen häufig davon aus, dass sich
Gattungen anhand konstant bleibender Features identifizieren lassen. Der Beitrag möchte
anhand des Minnesangs, aufzeigen, wie und dass sich gattungsgeschichtliche
Entwicklungen mit digitalen Methoden nachzeichnen lassen.
![Ausschnitt aus Abb. 3 des Beitrags: Stimmungsbilder verschiedener Topics: Ergebnisse der Sentiment-Analyse (Boxplot inkl. Mittelwert (kurze Linie) und Median (einfache Linie) sowie der Gesamtmittelwert (gestrichelte Linie) und die Nulllinie (durchgehende Linie)) der Artikel aufgeteilt nach Topics und sortiert nach Polarität. [Raven Adam / Marie Lisa Kogler / Martina Scholger 2023]](/sites/default/files/styles/medium/public/article_images/klimaschutz_003.png.webp?h=08e277e5&itok=XEb-nKbX)