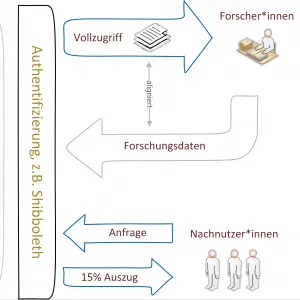
Das Projekt XSample entwickelt eine Lösung für die Nutzung urheberrechtlich geschützter Texte in der DH-Forschung. Der forschungsgesteuerte Ansatz ermöglicht eine Optimierung des maximal erlaubten Auszugsvolumens entlang eigener Forschungsfragen.
When working with digitized historical prints researchers frequently find themselves confronted with unclear copyright settings. This article therefore not only tries to give guidelines on how to deal with these problems, but also offers two case studies including legal and technical solutions for creation and reuse of individual data sets.
Das Text und Data Mining (TDM) mit urheberrechtlich geschützten Texten unterliegt trotz der TDM-Schranke (§ 60d UrhG) weiterhin Einschränkungen, die u. a. die Speicherung, Veröffentlichung und Nachnutzung der entstehenden Korpora betreffen und das volle Potenzial des TDM in den Digital Humanities ungenutzt lassen.