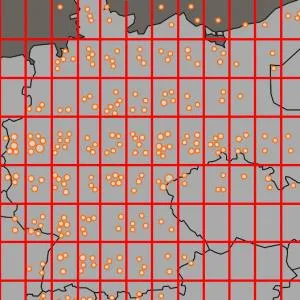
Auktionskataloge sind wichtige Quellen für die historische Sammlungsforschung. Mit Hilfe von methodischen Ansätzen aus den Bereichen natural language processing, data mining und distant reading geht der Beitrag den Interessen des Sammlers Johann Gottfried Lakemacher nach, der als typischer Gelehrter seiner Zeit gelten kann.
Texte von beschrifteten Bildkarten des Leibniz-Zentrums für Archäologie (LEIZA) wurden mit zwei Methoden erschlossen: mit einer klassischen Deep-Learning-Pipeline sowie mit Large-Language-Modellen (LLMs) wie GPT-4o.
The Article displays the current state of research on generative AI applications in digital scholarly editing. Based on workshops at the DHd 2024 it identifies eight key application areas for LLM and concludes by identifying critical areas from practical as well as theoretical perspectives.
When working with digitized historical prints researchers frequently find themselves confronted with unclear copyright settings. This article therefore not only tries to give guidelines on how to deal with these problems, but also offers two case studies including legal and technical solutions for creation and reuse of individual data sets.
Der Bomber’s Baedeker wurde während des Zweiten Weltkrieges vom britischen Foreign Office und dem Ministry of Economic Warfare erstellt. 2019 wurde er (wieder-)entdeckt, digital erschlossen, aufbereitet und so der weiteren Bearbeitung und Analyse unter Einhaltung der FAIR-Prinzipien als offene, maschinenlesbare Datenquelle zugänglich gemacht.
In den Digital Humanities herrscht latent die
Auffassung, dass über den Einsatz generischer Werkzeuge eine Brücke zwischen den
einzelnen Fachwissenschaften geschlagen werden kann oder soll. Dabei werden zu leicht Unterschiede im
Erkenntnisinteresse und in der Hermeneutik übersehen.




![: General model of scholarly editing as knowledge production workflow: from source material to data and publication, through intermediate ›products‹ (middle), concrete steps (right), and more general challenges (left). [Pollin et al. 2025]](/sites/default/files/styles/medium/public/article_images/generative_ai_001.png.webp?itok=V2xgk_nN)