DOI: 10.17175/sb001_006
Nachweis im OPAC der Herzog August Bibliothek: 830166564
Erstveröffentlichung: 19.02.2015
Lizenz: Sofern nicht anders angegeben 
Medienlizenzen: Medienrechte liegen bei den Autoren
Letzte Überprüfung aller Verweise: 31.05.2016
GND-Verschlagwortung: Hermeneutik | Ontologie (Wissensverarbeitung) | Informatik |
Empfohlene Zitierweise: Evelyn Gius, Janina Jacke: Informatik und Hermeneutik. Zum Mehrwert interdisziplinärer Textanalyse. In: Grenzen und Möglichkeiten der Digital Humanities. Hg. von Constanze Baum / Thomas Stäcker. 2015 (= Sonderband der Zeitschrift für digitale Geisteswissenschaften, 1). text/html Format. DOI: 10.17175/sb001_006
Abstract
Der Beitrag verhandelt die methodologischen Konsequenzen der interdisziplinären Zusammenarbeit zwischen Geisteswissenschaft und Informatik im Kontext des heureCLÉA-Projekts. Ziel von heureCLÉA ist es, eine ›digitale Heuristik‹ zur narratologischen Analyse literarischer Texte zu entwickeln, mit der automatisiert (1) bislang nur manuell durchführbare Annotationsaufgaben bis zu einem bestimmten Komplexitätsniveau durchgeführt und (2) statistisch auffällige Textphänomene als Kandidaten für eine anschließende Detailanalyse durch den menschlichen Nutzer identifiziert werden können.
Bei diesem Projekt müssen die disziplinären Herangehensweisen in besonderem Maß berücksichtigt werden. Im vorliegenden Beitrag werden die Ansätze dargestellt, die das bestehende Spannungsfeld zwischen (nicht-deterministischer) geisteswissenschaftlicher Hermeneutik und (deterministischer) Informatik produktiv nutzen und so über die konkrete Fragestellung des Projekts hinauswirken.
This paper discusses the methodological effects of the interdisciplinary cooperation between humanities scholars and computer scientists in the context of the project heureCLÉA. The goal of heureCLÉA is to develop a ›digital heuristic‹ that supports the narratological analysis of literary texts by (1) performing automatically annotation tasks up to a certain level of complexity that previously could only be carried out manually, and by (2) identifying statistically salient text phenomena for the subsequent detailed analysis by the human user.
In this project, it was essential to devote special attention to the specific disciplinary approaches. In this paper, we illustrate the ways in which the tensions between (non-deterministic) hermeneutics in the humanities and (deterministic) computer science can be productively employed and thus have an effect beyond the concrete research question.
- 1. Einleitung
- 2. Die Rolle der Hermeneutik
- 2.1 Hermeneutik und Narratologie
- 2.2 Hermeneutisches Markup
- 3. Wechselwirkungen literaturwissenschaftlicher und informatischer Textanalyse
- 3.1 Zur Häufigkeit der betrachteten Phänomene
- 3.2 Zur Vielfalt der Analysen
- 3.3 Konsequenzen
- 3.4 Der Mehrwert für die Narratologie
- 4. Fazit
- Bibliographische Angaben
- Abbildungslegenden und -nachweise
1. Einleitung
Die Frage danach, was Digital Humanities sind, ist ähnlich alt wie die Digital Humanities selbst. Im Laufe der Jahrzehnte hat sich die Bezeichnung des Diskutierten mehrfach geändert: Die Digital Humanities hießen und heißen auch Computing in the Humanities, Literary Computing, Humanities Computing, eHumanities oder – im deutschen Sprachraum – ›Computerphilologie‹ und bezeichnen aus Sicht der Community mal eine Methode, mal eine Disziplin oder beliebige Kombinationen daraus.[1] Gemeinsam ist den Definitionen aber allen, dass es bei Digital Humanities um eine – wie auch immer geartete – Kombination von Aspekten der Geisteswissenschaften und der Informationswissenschaften geht. Das Zusammenspiel der beteiligten Disziplinen kann sehr unterschiedlich gestaltet sein, wobei der disziplinäre Ursprung der verfolgten Fragestellung(en) eine Klassifizierungsmöglichkeit von Digital Humanities-Forschungsprojekten jenseits ihrer Definition darstellt.[2] Je nachdem, ob die dem betrachteten Forschungsansatz zugrundeliegenden Fragestellungen aus dem Bereich der Geisteswissenschaft oder aus der Informatik stammen, lassen sich drei Kategorien von Digital Humanities-Projekten bestimmen (vgl. Abbildung 1): Erstens Projekte, die geisteswissenschaftliche Fragestellungen verfolgen (und dafür auch informatische Methoden anwenden), zweitens Projekte, deren Fragestellungen aus der Informatik stammen (die auch mit geisteswissenschaftlichen Methoden bearbeitet werden) und drittens Projekte, die Fragestellungen sowohl aus den Geisteswissenschaften als auch aus der Informatik behandeln.

Dieser Beitrag beleuchtet den Mehrwert des im Forschungsprojekt heureCLÉA verfolgten Zugangs, der unter die dritte Kategorie von Digital Humanities-Forschungsprojekten fällt.[3] Wir wollen insbesondere aufzeigen, welche Konsequenzen das Zusammenwirken von geistes- und informationswissenschaftlichen Zugängen in ein- und demselben Projekt haben kann und wie die interdisziplinäre Auseinandersetzung mit diesen Fragestellungen einen Mehrwert generiert, der durch die spezielle Situation solcher Forschungsvorhaben besonders gefördert, wenn nicht sogar erst ermöglicht wird. Dabei stehen weniger die Ergebnisse unserer Arbeit im Fokus, sondern wir wollen vielmehr die disziplinären methodischen und methodologischen Konsequenzen der Zusammenarbeit darstellen.
Im Projekt heureCLÉA arbeiten Informatiker und Literaturwissenschaftlerinnen an einer so genannten ›digitalen Heuristik‹, die die Analyse von literarischen Texten unterstützen soll. Die geisteswissenschaftliche Problemstellung für das Projekt heureCLÉA ist dabei die Erschließung und Annotation von narrativen Referenzen im Feld der Grundkategorie ›Zeit‹ anhand eines Korpus von literarischen Erzählungen. Die Fragestellung seitens der Informatik bzw. der Sprachverarbeitung (auch Natural Language Processing bzw. NLP) betrifft die Neuentwicklung von Data Mining-Methoden für die bislang unbearbeitete Domäne literarischer Texte. heureCLÉA ist damit ein Projekt, das Fragestellungen aus der Narratologie und aus der Sprachverarbeitung vereint.
Ziel des Projekts ist die Entwicklung eines heuristischen Moduls, das die Funktionalität der webbasierten Textanalyse und -annotationsumgebung CATMA[4] erweitert, indem es Vorschläge zu narratologischen Phänomenen in einem Text anbietet. Im Fokus stehen dabei klassische narratologische Kategorien, die das zeitliche Verhältnis zwischen Erzähltem und Erzählen thematisieren – wie etwa die Kategorien Ordnung (In welcher Reihenfolge?), Frequenz (Wie oft?) und Dauer (Wie lange?).[5]
Das Modul wird auf der Basis von drei Zugängen entwickelt: (1) Ausgangspunkt ist die Annotation der Zeitphänomene, die von geschulten Annotatoren vorgenommen wird.[6] Dieses Markup wird anschließend mit (2) regelbasierten Verfahren[7] sowie (3) Machine-Learning-Ansätzen kombiniert, um eine Vorhersage der Phänomene in literarischen Texten zu entwickeln.[8]
Aufgrund des Zusammenspiels von literaturwissenschaftlichen – und speziell: hermeneutischen – Verfahren und informatischen Verfahren des Data Mining stehen sich non-deterministische Zugänge zu Texten und entscheidbare bzw. deterministische Verfahren gegenüber, die nicht problemlos auf den jeweils anderen Ansatz übertragen werden können. Deshalb ist die Reproduzierbarkeit von narratologischen Analysen für die Vereinbarkeit des literaturwissenschaftlichen und des informatischen Zugangs und damit für den Erfolg des heuristischen Moduls ausschlaggebend. Andererseits ist gerade die Reproduzierbarkeit von Analyseergebnissen im Bereich der literaturwissenschaftlichen Textanalyse ein problematisches Konzept, da sie nicht ohne Weiteres mit den Prinzipien von hermeneutischen Verfahren vereinbar ist.
Das sich in diesem Gegensatz abzeichnende Problemfeld soll im verbleibenden Artikel differenzierter dargestellt werden. Dafür werden wir zuerst in Abschnitt 2 auf die generelle Rolle der Hermeneutik in der Narratologie und ihre Bedeutung für die Wahl eines geeigneten Annotationzugangs für das heureCLÉA-Projekt eingehen. Anschließend beschreiben wir die in der Zusammenarbeit zwischen (hermeneutisch geprägter) Narratologie und (nicht hermeneutisch ausgerichteter) Computerlinguistik auftretenden Wechselwirkungen in Abschnitt 3. Dabei stehen insbesondere die Fragen nach Umfang und Vielfalt der analysierten bzw. genutzten Daten im Fokus, deren Problematik sich an den beiden gegensätzlichen Konzeptpaaren Exemplarität vs. sparsity und Interpretationsvielfalt vs. noise festmachen lässt. Für beide Fälle beschreiben wir die fachdisziplinären Konsequenzen sowie die entwickelten Lösungsansätze. Ein besonderes Augenmerk richten wir im letzten Teil des Abschnitts auf die Folgen für die Narratologie, die bereits jetzt, nach etwa der Hälfte der Projektlaufzeit, von erheblicher Bedeutung sind. Schließlich fassen wir die methodologischen Vorteile des interdisziplinären Ansatzes in Abschnitt 4 zusammen.
2. Die Rolle der Hermeneutik
2.1 Hermeneutik und Narratologie
Die Hermeneutik – die »Methodenlehre des Interpretierens von Rede und Text«[9] – dient bereits in der Antike der Auslegung religiöser Schriften und spielt heute, nach ihrer Neuprägung u.a. durch Schleiermacher und Dilthey,[10] vor allem in der Literaturwissenschaft eine wichtige Rolle. Dort ist mit ›hermeneutischem Textverstehen‹ meist eine ganz spezielle Operation gemeint: Das Herausarbeiten dessen, »was man für die Bedeutung (oder den Sinn bzw. den Inhalt) eines Werkes oder seiner Bestandteile hält«.[11] Der vorherrschenden Meinung zufolge zeichnet sich derartiges Textverstehen unweigerlich durch eine ganz bestimmte Struktur aus, die dadurch charakterisiert ist, dass Vorannahmen von Textinterpreten, Annahmen über Textteile und Annahmen über das Textganze sich immer wieder gegenseitig beeinflussen, was zu Modifikationen bzw. zur Bestätigung dieser einzelnen Annahmen führt.[12]
Im Projekt heureCLÉA geht es weniger um die Methodenlehre des Interpretierens, sondern vielmehr um hermeneutische Textauslegung selbst im Rahmen narratologischer Textanalyse: Die Narratologie ist eine literaturwissenschaftliche Disziplin, die eine Reihe theoretischer Konzepte und Modelle für die Analyse und Interpretation erzählender Texte zur Verfügung stellt. Diese narratologischen Kategorien dienen der Bezeichnung und Verortung textueller Eigenschaften, die (a) als typisch für narrative Texte angesehen werden und (b) in unterschiedlicher Hinsicht als Basis der Textinterpretation dienen.[13] Viele der Kategorien fassen strukturelle Phänomene, die hauptsächlich an der Textoberfläche zugänglich sind.
Die Narratologie gilt aufgrund dieser Ausrichtung auf primär textuelle Eigenschaften als Methode zur kontextunabhängigen Analyse von Erzähltexten, die ohne Bezüge zu extratextuellen Kontexten auskommt.[14] Daraus wird häufig geschlossen, dass die Narratologie eine interpretationsunabhängige Methode zur Verfügung stellt.[15] Kontextunabhängigkeit ist allerdings nicht gleichbedeutend mit Interpretationsunabhängigkeit – jedenfalls nicht im weiteren Sinne von ›Interpretation‹: Die meisten narratologisch beschriebenen Phänomene sind zwar an der Textoberfläche zugänglich, die für ihre Anwendung notwendige Rekonstruktion der sprachlichen Textbedeutung kann aber auch interpretationsabhängige Aspekte wie Disambiguierung oder Erschließung von Implikationen beinhalten und ist damit in einem weiteren Sinne des Wortes interpretativ, das heißt: Interpreten können mitunter legitimerweise zu unterschiedlichen Auffassungen darüber gelangen, was im Text ausgedrückt wird, da die Bedeutung nicht immer notwendig aus dem Textmaterial folgt. So ist beispielsweise sprachliches Verstehen – und damit die Anwendung nicht-deduktiver Schlüsse – notwendig, um etwa die zeitliche Ordnung von Erzählungen zu analysieren; auch wenn zunächst vielleicht der Verdacht naheliegt, dass diese sich allein aufgrund eindeutiger Textmarker wie etwa dem Tempus feststellen lässt.[16] Basiert eine Erklärung auf sprachlichem Verstehen, so ist sie nicht notwendigerweise der einzige richtige Schluss, da sie auf einer Interpretation bzw. Gewichtung von ggf. widersprüchlichen Aspekten beruht und nicht ausschließlich von Phänomenen der Textoberfläche abgeleitet werden kann. Schon bei derartigen Schlüssen kann eine Variante des oben skizzierten Verfahrens hermeneutischen Textverstehens zum Tragen kommen, wenn Bedeutungshypothesen in wechselnder Bezugnahme auf die fragliche Textstelle, den weiteren intratextuellen Kontext und eventuell auf intersubjektiv geteilte Vorannahmen (wie allgemeines Weltwissen) generiert, modifiziert und bestätigt werden.
Indem wir Texte mithilfe von narratologischen Kategorien analysieren, bewegen wir uns also zwischen rein formaler Textbeschreibung und Hermeneutik: Zwar kann man generell davon ausgehen, dass narratologische Kategorien der Klassifizierung bzw. Beschreibung von Texten dienen[17] und damit keinen primären Fokus auf hermeneutische Verfahren haben. Gleichzeitig ist auch die narratologische Analyse ein hermeneutisches und damit ein interpretatives Verfahren. Interpretation ist für die Narratologie genau genommen in dreierlei Hinsicht relevant:
(1) Narratologische Textbeschreibungen können potentiell als Grundlage, Prüfstein oder Heuristik umfassender Werkdeutungen dienen.[18] (2) Die narratologische Analyse geht meist über eine rein formale bzw. quantitative Textbeschreibung hinaus, da – wie oben bereits dargelegt – sprachliches Verstehen involviert ist. Dieses führt zwar meist, aber nicht immer zu intersubjektiv gültigen Ergebnissen.[19] (3) Es gibt Fälle, in denen der narratologischen Klassifikation eine Textdeutung vorausgehen muss, da das zu bestimmende Phänomen nur aufgrund einer umfassenden Textinterpretation erschlossen werden kann.[20]
Während der erste Punkt nur dann zum Tragen kommt, wenn umfassende Werkinterpretationen erstellt werden, sind die beiden anderen Aspekte potentiell in jeder narratologischen Textanalyse von Belang. Damit ist auch die narratologische Textanalyse trotz ihres vergleichsweise formalen Zugangs ein eindeutig hermeneutisches Verfahren. Entsprechend ist die Arbeit im heureCLÉA-Projekt stark von dem typischen Gegensatz zwischen Geisteswissenschaft und Informatik bzw. non-deterministischen und deterministischen Arbeitsweisen geprägt.
2.2 Hermeneutisches Markup
Bereits im Vorfeld der tatsächlichen Zusammenarbeit zwischen Narratologie und Computerlinguistik musste eine wichtige Frage geklärt werden: Wie können hermeneutische Verfahren der Textanalyse in ein adäquates maschinenlesbares Format übersetzt werden? Dabei ging es darum, einen Annotationszugang zu identifizieren, der eine nicht-deterministische Textanalyse, wie sie im Projekt heureCLÉA vorgenommen wird, unterstützt. Hierfür sind nicht alle Markup-Typen, die für die Annotation von Texten genutzt werden, geeignet.
Grundsätzlich kann man zum einen die Verbindung zwischen Markup und annotiertem Objekt, zum anderen die Funktion des Markups unterscheiden. Die Unterteilung in eingebettetes oder inline-Markup, das direkt in den annotierten Text geschrieben wird, und stand-off-Markup, das separat abgespeichert wird und durch abgespeicherte Verweise auf die jeweiligen Textabschnitte referiert, ist nicht nur technisch von Belang. Mit der Wahl der Verbindung zwischen Markup und annotiertem Objekt sind auch verschiedene methodologische Zugänge zur Textanalyse verbunden: Während mit einer fest mit dem Text verzahnten inline-Annotation – zumindest implizit – ein normativer Zugang zur Textanalyse und damit ein gewisser Anspruch auf objektive und zeitlose ontologische Gültigkeit verbunden ist, ist die stand-off-Annotation flexibler und ermöglicht vielfältige und vielschichtige Zuschreibungen an einen Text. Damit ist sie näher am oben diskutierten Gedanken der hermeneutischen Textanalyse, der seit Dilthey und Gadamer in den Geisteswissenschaften vorherrscht. Um sinnvoll literaturwissenschaftlich arbeiten zu können, braucht man insbesondere ein Markup, das verschiedene Interpretationen derselben Textstelle ermöglicht, indem es verschiedene Auszeichnungen dieser Textstelle gleichzeitig zulässt. Dabei heißt ›verschieden‹ nicht nur ›unterschiedlich‹, sondern dies muss auch die Möglichkeit widersprüchlicher Annotationen mit einschließen. Wie wir in Abschnitt 3.3 sehen werden, kann es nämlich durchaus vorkommen, dass zwei Analysen einer Textstelle zu Ergebnissen kommen, die sich gegenseitig ausschließen, und die Stelle entsprechend mit widersprüchlichen Annotationen versehen wird. Auch wenn solche direkten Widersprüche zumeist durch die jeweilig damit verbundenen unterschiedlichen Vorannahmen bedingt sind und es entsprechend möglich ist, die Unstimmigkeiten aufzuklären, so führt eine solche Klärung in vielen Fällen nicht zu einer übereinstimmenden Bewertung der Textstelle, sondern eher zu einer Art Einigkeit über die Uneinigkeit in der Bewertung. Entsprechend muss es für eine literaturwissenschaftliche Textanalyse möglich sein, sich gegenseitig ausschließende Annotationen für dieselbe Zeichenkette vorzunehmen.[21]
Der zweite Unterschied zwischen Annotationszugängen betrifft die Funktion des zur Verfügung gestellten Markups. Hier geht es gewissermaßen um die Frage, für wen das Markup bestimmt ist: Soll eine Maschine mit so genanntem prozeduralen Markup angewiesen werden, eine bestimmte Operation auszuführen (z.B. den Text auf eine bestimmte Weise – etwa als Überschrift – darzustellen) oder soll ein deskriptives Markup einen menschlichen Adressaten über die Kategorisierung eines bestimmten Textabschnittes (im Kontext einer Grammatik, eines Lexikons oder auch eines bestimmten pragmatischen Zusammenhangs) informieren? Vor fast zwei Jahrzehnten haben Coombs et al. bereits festgestellt, dass nur deskriptives Markup den intellektuellen Zielen wissenschaftlicher Textanalysen gerecht werden kann.[22] Piez hat diesen Ansatz weiterentwickelt und den Begriff des hermeneutischen Markups geprägt:
»By ›hermeneutic‹ markup I mean markup that is deliberately interpretive. It is not limited to describing aspects or features of a text that can be formally defined and objectively verified. Instead, it is devoted to recording a scholar's or analyst's observations and conjectures in an open-ended way. As markup, it is capable of automated and semiautomated processing, so that it can be processed at scale and transformed into different representations. By means of a markup regimen perhaps peculiar to itself, a text would be exposed to further processing such as text analysis, visualization or rendition. Texts subjected to consistent interpretive methodologies, or different interpretive methodologies applied to the same text, can be compared. Rather than being devoted primarily to supporting data interchange and reuse – although these benefits would not be excluded – hermeneutic markup is focused on the presentation and explication of the interpretation it expresses.«[23]
Für die Arbeit in heureCLÉA wird ein solches ›hermeneutisches Markup‹ in Form von deskriptivem stand-off-Markup genutzt, das in CATMA implementiert ist.[24] Dieses ermöglicht nicht nur mehrfache, überlappende und sogar widersprüchliche Annotationen derselben Textstelle, sondern erlaubt auch eine flexible Gestaltung der genutzten Analysekategorien. Diese können bei Bedarf im Laufe der Annotationsdurchgänge modifiziert und angepasst werden, wobei CATMA zusätzlich durch die implementierten Suchfunktionen eine halbautomatische Veränderung der Annotationen zulässt. Diese Flexibilität von CATMA unterstützt die durch die Praxis der hermeneutischen Textanalyse bedingte rekursive Überarbeitung der Annotationen und damit den gesamten literaturwissenschaftlichen Textanalyseprozess erheblich. Deshalb wird das von CATMA zur Verfügung gestellte Annotationsformat auch im Projekt heureCLÉA genutzt.
3. Wechselwirkungen literaturwissenschaftlicher und informatischer
Textanalyse
Wenn zwei so unterschiedliche Disziplinen wie Literaturwissenschaft und Informatik im Rahmen eines Projekts wie heureCLÉA kooperieren, dann rücken unweigerlich einige theoretische und praktische Differenzen zwischen den Fachwissenschaften in den Fokus, die im Laufe des Projekts analysiert und konstruktiv bearbeitet werden müssen. So kommt es vor, dass bestimmte Fachtermini zwar in beiden beteiligten Disziplinen genutzt werden, diese Termini jedoch jeweils unterschiedlich definiert sind – so zum Beispiel die Ausdrücke ›Ereignis‹ und ›narrativ‹. Diesen rein terminologischen Missverhältnissen ist leicht durch das Offenlegen der fachspezifischen Definitionen Abhilfe zu schaffen: Während in der Sprachverarbeitung (Natural Language Processing bzw. NLP) die Definition von ›Ereignis‹ bzw. ›event‹ grundsätzlich möglichst allgemein gehalten wird als etwas, das auftritt oder passiert und eine zeitliche Dimension hat, ist der Ereignisbegriff in der Narratologie wesentlich detaillierter.[25] Als Ereignis gilt dort eine erzählte Zustandsveränderung (diese Bestimmung ist auch bekannt unter der Bezeichnung ›Ereignis I‹) bzw. eine erzählte Zustandsveränderung, der zusätzliche Eigenschaften wie bspw. Faktizität und Resultativität – also tatsächliches Eintreten und Abgeschlossenheit der Zustandsveränderung in der fiktiven Welt einer Erzählung – zukommen (auch ›Ereignis II‹).[26]
Eine zweite Differenz erfordert hingegen komplexere Maßnahmen, um eine Zusammenarbeit zu ermöglichen. Das Problem besteht darin, dass die Qualität der vorgenommenen bzw. genutzten Analysen in den beiden Fachdisziplinen traditionell unterschiedlich bewertet wird: Das, was in der NLP als nicht geeignete Datengrundlage betrachtet wird, kann aus Sicht der Literaturwissenschaft eine methodisch einwandfreie Analyse sein.
Im Folgenden möchten wir die zwei wesentlichen Aspekte dieser Problematik vorstellen. Zum einen geht es in Abschnitt 3.1 um die unterschiedliche Bewertung der geeigneten Menge an Analysedaten – also um das Spannungsverhältnis zwischen sparsity (Datenarmut) und exemplarischen Analysen –, und zum anderen um das ideale Maß an übereinstimmenden Analysen – also um den Widerspruch zwischen noise (nicht verwertbaren, widersprüchlichen Daten) und Interpretationspluralismus (Abschnitt 3.2). Dass derartige fachwissenschaftliche Unterschiede nicht nur pragmatisch aufgelöst werden können, sondern letztlich auch noch einen Mehrwert für die einzelnen Fachdisziplinen bedeuten können, soll in den Abschnitten 3.3 und 3.4 gezeigt werden.
3.1 Zur Häufigkeit der betrachteten Phänomene
In der NLP wird für die Automatisierung von Aufgaben der Texterkennung auf eine möglichst große Datenbasis zurückgegriffen, um daraus statistisch signifikante Regelhaftigkeiten abzuleiten, die etwa die Verteilung von Phänomenen in einem bestimmten Text vorhersagen können. Im Rahmen eines solchen statistischen Zugangs zur Verarbeitung natürlicher Sprache sind selten vorkommende Phänomene entsprechend problematisch, da sie nicht in ausreichender Zahl vorhanden sind, um eine verlässliche Basis für Inferenzen zu bilden. Dieses je nach Kontext als sparse data oder rare events bezeichnete Problem tritt notwendigerweise bei jeder Analyse auf: Während die Zahl der häufig vorkommenden Sprachphänomene limitiert ist und sich entsprechend mit einer geeigneten Korpuserstellung fassen lässt, ist es oft nicht möglich, ausreichend Daten für eine erschöpfende Analyse selten vorkommender Phänomene zusammenzustellen.[27] Je nach Problemstellung ist es deshalb in der statistischen NLP gängig, selten vorkommende Phänomene aus dem Korpus zu entfernen. Dies gilt insbesondere für jene Fälle, in denen die Parameter zur Modellierung der Phänomene ausschließlich aus einem Trainingskorpus erschlossen werden.[28]
Während also möglichst zahlreiche Vorkommnisse der untersuchten Phänomene in der automatisierten Sprachverarbeitung das vorherrschende Desiderat sind, ist umgekehrt die exemplarische Analyse von Einzelfällen die in der Literaturwissenschaft gängige Praxis. Dafür, dass Textanalysen bzw. Interpretationen sich meist auf die Bearbeitung eines oder weniger Werke beschränken, gibt es zwei Gründe. Zum einen entspricht, gerade im Zusammenhang mit umfassenden Textinterpretationen, das Herausstellen der besonderen Eigenschaften eines Einzelwerks oder einzelnen Autors dem Selbstverständnis der Literaturwissenschaft: »[D]ie Anstrengung der Literaturwissenschaft [gilt] gerade dem Besonderen des Textes. […] Von literarischer Bedeutung zu sprechen, heißt von der Ausnahme der Regel zu sprechen.«[29] Zum anderen gibt es für die exemplarische Arbeitsweise auch praktische Gründe: Selbst wenn es Literaturwissenschaftlern darum geht, durch Textanalyse und -interpretation Erkenntnisse zu erlangen, die auf bestimmte andere Texte übertragbar sein sollen, ist es oft aus praktischen Gründen nicht möglich, ein großes Textkorpus zu bearbeiten. Das liegt daran, dass literaturwissenschaftliche Textarbeit – und insbesondere stark textorientierte Zugänge wie etwa die narratologische Analyse – sehr genaue und mehrmalige Rezeption sowie textnahe Detailanalysen erforderlich machen.
3.2 Zur Vielfalt der Analysen
Für die automatische Sprachverarbeitung sollte das genutzte Datenmaterial nicht nur möglichst zahlreiche Vorkommnisse der untersuchten Phänomene aufweisen, diese sollten außerdem möglichst eindeutig sein, um den statistischen Fehler von Vorhersagen zu minimieren. Das heißt unter anderem, dass etwa bei von mehreren Personen annotierten Daten die Annotationen übereinstimmen sollten. Als Datengrundlage für Training und Evaluation von NLP-Systemen wird häufig mit einem so genannten ›Goldstandard‹ gearbeitet, der eine hohe Konsistenz des Datenmaterials garantieren soll, indem Annotationen von mehreren Personen nach genau festgelegten Annotationsrichtlinien manuell erstellt und verglichen werden.[30]
Daten, die vielfältige oder gar widersprüchliche Informationen enthalten, werden hingegen als ›noisy‹ bezeichnet – und das Rauschen, das sie enthalten, wird in den meisten Zugängen entfernt, da es sich dabei um nicht-deterministisches und damit aus Sicht der NLP um nicht geeignetes Material handelt.[31]
Die Tatsache, dass literarische Texte von Interpreten unterschiedlich verstanden werden (können), wird in der Literaturwissenschaft hingegen als durch den Gegenstand und die Methode bedingt und damit als normal, wenn nicht sogar notwendig betrachtet. Für den in der Literaturwissenschaft geltenden Interpretationspluralismus gibt es mindestens drei Gründe: (1) Der wohl wichtigste Grund liegt in der Annahme der grundsätzlichen Polyvalenz literarischer Texte.[32] Dieser These zufolge ist es ein charakteristisches Merkmal literarischer Texte, dass sie sich unterschiedlich deuten lassen. Die verschiedenen Deutungen sind oft gleichwertig und können einander widersprechen. Unter dieser Voraussetzung muss die generelle Vereinheitlichung unterschiedlicher Interpretationen als Missachtung der Mehrdeutigkeit literarischer Texte gewertet werden. (2) Ein weiterer Grund für den in der Literaturwissenschaft akzeptierten Interpretationspluralismus, der möglicherweise mit der Polyvalenz literarischer Texte zusammenhängt, ist die Mehrdeutigkeit des Verstehens- bzw. Bedeutungsbegriffs. Textinterpretation ist auf das Verstehen von Texten bzw. auf das Erfassen ihrer Bedeutung ausgerichtet. Dabei muss jedoch unter ›Bedeutung‹ nicht immer das Gleiche verstanden werden. Nach Danneberg liegt jeder Textinterpretation implizit oder explizit eine Bedeutungskonzeption zugrunde, die festlegt, was im Rahmen dieser Interpretation als Textbedeutung verstanden wird bzw. wie sich diese konstituiert.[33] Die Bedeutungskonzeption kann hierbei autor-, text-, rezipienten- oder kontextorientiert sein.[34] Liegen also zwei konkurrierende Interpretationen eines Textes oder eines Textteils vor, so kann der Grund dafür sein, dass sich die Interpretationen auf unterschiedliche Bedeutungskonzeptionen stützen. (3) Zusätzlich zu den beiden bisher genannten Punkten muss beachtet werden, dass Interpretationen immer Operationen sind, bei denen nicht-deduktive Schlüsse wie beispielsweise Abduktion (Schluss auf die beste Erklärung) vollzogen werden müssen.[35] Bei solchen Schlüssen geht es darum herauszufinden, was durch einen Text impliziert ist, wobei es möglich ist, dass zwei Interpreten auf Basis des gleichen Textes zu unterschiedlichen Ergebnissen kommen, die jedoch beide zulässig sein können. Eine derartige Situation liegt im oben diskutierten Beispiel zum Tempuswechsel[36] vor, in dem die anscheinend beste Erklärung der Textdaten diejenige ist, dass der Tempuswechsel keine Abweichung von der chronologischen Darstellung bedeutet. Ob diese Folgerung allerdings tatsächlich durch den Text impliziert wird, ist in ähnlichen Fällen nicht immer vollends klar, weswegen dann auch andere Folgerungen sinnvoll sein können.
3.3 Konsequenzen
Die oben beschriebenen inkompatiblen fachspezifischen Sichtweisen auf die Frage von Umfang und Vielfalt der erzeugten bzw. genutzten Daten erforderten Maßnahmen auf beiden Seiten, um überhaupt gemeinsam am heureCLÉA-Projekt arbeiten zu können: Da die Annotation der Daten der erste Schritt bei der Entwicklung der digitalen Heuristik ist, musste als erstes auf narratologischer Seite überlegt werden, inwiefern die Problematiken von sparsity und noise bei der Auswahl und Analyse der Texte verringert werden können. Für die darauf folgenden Schritte der regelbasierten Verfahren und Machine Learning-Ansätze musste anschließend auf Seite der Computerlinguistik ein Weg gefunden werden, der auch den literaturwissenschaftlichen Prinzipien der Exemplarität und der Interpretationsvielfalt gerecht wird. Wie wir im Folgenden zeigen werden, haben diese Maßnahmen nicht nur zur Annäherung von jeweils gegensätzlichen Positionen geführt, sondern wirken sich auch – z.T. weit über das Projektziel einer digitalen Heuristik hinaus – positiv auf Fragestellungen der beiden Fachdisziplinen aus.
Das durch die Exemplarität literaturwissenschaftlicher Textanalyse bedingte sparsity-Problem wird im Rahmen des Projekts heureCLÉA nur durch den zweiten der in Abschnitt 3.1 genannten Gründe für exemplarisches Arbeiten bedingt: In heureCLÉA spielt die durch umfassende Interpretation herauszustellende Werkbedeutung und damit die Besonderheit des einzelnen Textes keine Rolle. Die narratologische Analyse erfordert aber sehr wohl genaue und damit zeitintensive Textarbeit, weshalb keine große Menge an Texten annotiert werden kann. Gleichzeitig ist unser Anspruch an die digitale Heuristik, die auf Basis unserer Analysen erstellt wird, dass sie auf möglichst viele – unterschiedliche – narrative Texte anwendbar sein soll. Deshalb ist die Vorgehensweise in heureCLÉA trotz der praktischen Einschränkung durch den hohen Arbeitsaufwand literaturwissenschaftlicher Analysen in zweierlei Hinsicht darauf ausgerichtet, verallgemeinerbare Ergebnisse zu erzielen:
(1) Textgrundlage: Damit unser Modul letztlich nicht nur an die Eigenheiten eines Einzelwerks angepasst ist, arbeiten wir mit 21 Erzählungen unterschiedlicher Autoren. Auf diese Weise wird für eine zumindest teilweise heterogene Datengrundlage gesorgt, so dass die Chance der Übertragbarkeit der Ergebnisse auf weitere Texte gefördert wird. Um in einem ersten Schritt verwertbare Ergebnisse erzielen zu können, sind die Texte unseres Korpus nicht in jeder Hinsicht heterogen, sondern größtenteils in der gleichen Zeitspanne (um 1900) entstanden. Die weitere Verallgemeinerbarkeit der Ergebnisse kann im Anschluss – etwa mit Erzähltexten aus anderen Zeiträumen oder mit anderem Umfang – erprobt werden.
(2) Interpreten: Um außerdem dafür zu sorgen, dass die Analysedaten in heureCLÉA nicht auf subjektiven Einzelmeinungen von Interpretinnen beruhen, wird jeder Text von mindestens zwei Annotatoren in wechselnden Teams bearbeitet. So wird gewährleistet, dass zu jedem Text zwar nicht eine große Menge an Metadaten, doch aber immer mehr als eine Analyse vorliegt, was wiederum der Repräsentativität der Ergebnisse zuspielt.
Beide genannten Vorgehensweisen ermöglichen eine gewissermaßen ›semi-exemplarische‹ Arbeitsweise und damit die Annäherung des literaturwissenschaftlichen Umgangs an die informatische Sichtweise: Die mögliche Nicht-Repräsentativität von Daten wird zumindest teilweise als Problem betrachtet und es werden Maßnahmen getroffen, um die daraus eventuell resultierenden Schwierigkeiten zu mildern.
Die Maßnahmen, die auf literaturwissenschaftlicher Seite getroffen wurden, mildern das Problem der Datenarmut, lösen es aber nicht. Im Kontext des heureCLÉA-Projekts ist nämlich nicht nur der reine Umfang der Texte im Korpus gering, auch das Vorkommen von expliziten Zeitausdrücken in den Texten beträgt – mit etwa einem expliziten Zeitausdruck auf 15 Sätzen – nur einen Bruchteil der Zeitausdrücke in nicht-fiktionalen narrativen Texten, auf denen die Analyse von Zeitinformationen im NLP-Bereich im Normalfall aufbaut. Erschwerend kommt hinzu, dass ausgerechnet explizite Zeitinformationen, die – bei adäquater Datengrundlage – von NLP-Zugängen besonders gut erkannt werden können, bei der Analyse von Zeitphänomenen im Bereich der Narratologie nur wenig interessant sind, da es dort um wesentlich komplexere Phänomene geht, die nicht zwingend mit Zeitausdrücken in Verbindung stehen.[37] Für die Entwicklung der digitalen Heuristik musste also auch seitens der NLP frühzeitig ein eigener Zugang entwickelt werden.
Dafür wurde in einem ersten Schritt das Tempus anstelle der Zeitausdrücke als Grundlage für die Bestimmung von Zeitinformationen gewählt, wodurch ein mehrfacher Vorteil entstand: Durch den Fokus auf das Tempus enthält die zur Verfügung stehende Datengrundlage trotz ihrer kleinen Größe ausreichend nutzbare Daten. Außerdem entspricht diese Strategie dem Ansatz von Mani und Schiffman zur Bestimmung der zeitlichen Ordnung narrativer Texte und passt damit sehr gut zur Fragestellung des Projekts.[38] Die Bestimmung des Tempus erfolgt über die Kombination einer Infrastruktur in Form einer UIMA-Pipeline, die automatisch verschieden komplexe Annotationen vornimmt, Teilsätze bestimmt sowie eine morphologische Analyse durchführt, und einer Heuristik, die anschließend das Tempus anhand von Textmarkern bestimmt.
Dieser kombinierte Zugang hat sich bisher als robust herausgestellt und kann außerdem im Gegensatz zu anderen Zugängen domänenunabhängig eingesetzt werden.[39] Im weiteren Projektverlauf werden die so generierten Annotationen von menschlichen Annotatorinnen überprüft und so in einem überwachten System eingesetzt, das die kontextabhängige Gültigkeit der Heuristik lernt. Damit ist also anscheinend eine für das Spannungsfeld Exemplarität und sparsity angemessene Lösung gefunden, die den beteiligten fachdisziplinären Methoden und Annahmen gerecht wird.
Um hingegen das durch die Interpretationsvielfalt bedingte noise-Problem für die Automatisierung besser handhabbar zu machen, wurde bei der narratologischen Analyse die Menge zugelassener Interpretationen in heureCLÉA regelhaft eingeschränkt. Denn trotz des Interpretationspluralismus in der Literaturwissenschaft – und hier besteht wieder ein Anknüpfungspunkt an die Perspektive der Computerlinguistik – wird bei weitem nicht jede Interpretation als zulässig erachtet. Neben allgemeinen Kriterien wie Konsistenz und Kohärenz sowie spezifischen Regeln des jeweiligen Interpretationsansatzes gehen viele Literaturwissenschaftler davon aus, dass Interpretationen anhand des Textmaterials begründbar sein müssen – oder zumindest mit diesem vereinbar.[40] Beispiele für prominente Ansätze im immer noch vergleichsweise wenig reflektierten Bereich der Interpretationstheorie und -praxis, die die notwendige Kompatibilität von Interpretationen mit dem Textmaterial in den Fokus rücken, sind solche Ansätze, die die Methode des Schlusses auf die beste Erklärung[41] oder die hypothetisch-deduktive Methode auf die Literatur übertragen. So sieht die hypothetisch-deduktive Methode Føllesdal et al. zufolge folgendes Vorgehen bei der Literaturinterpretation vor: »Zuerst wird eine Hypothese aufgestellt [...] und dann leitet man daraus eine Reihe von Konsequenzen ab, von denen sich zeigen lässt, dass sie mit dem Text übereinstimmen.«[42]
Diesen theoretischen Grundannahmen, die die Anzahl der zulässigen Interpretationen einschränken, wird in heureCLÉA vor allem durch die Praxis Genüge getan, dass nach abgeschlossener individueller Annotation inkompatible Annotationen im Rahmen eines Vergleichsdurchgangs unter den Annotatoren diskutiert werden. Dabei müssen die individuellen Entscheidungen für widersprüchlich annotierte Textstellen begründet werden, was letztlich dazu führt, dass schlecht begründete Entscheidungen revidiert werden müssen. Bei diesem Abgleich der Annotationen zeigt sich aber auch häufig, dass der Grund für inkompatible Annotationen weniger in einer mangelhaften Begründung als vielmehr in der unzureichenden Definition der zugrundeliegenden narratologischen Kategorie besteht. Tritt dieser Fall auf, wird er zum Anlass genommen, diese theoretischen Unzulänglichkeiten möglichst zu beheben.[43] Wenn sich diskrepante Annotationen weder auf mangelhafte Begründungen noch auf unzureichende Definitionen des annotierten Phänomens zurückführen lassen, dann sollte es immerhin in den meisten Fällen möglich sein, den Grund für die unterschiedlichen Deutungen anzugeben, so dass jede Interpretation beispielsweise als relativ zu bestimmten Grundannahmen gesehen werden kann.[44] In solchen Fällen werden die inkompatiblen Annotationen durch eine Markierung in den Metadaten als widersprüchlich autorisiert und der individuelle Grund für die jeweilige Interpretation vermerkt. Auf diese Weise können scheinbare Inkonsistenzen in den Metadaten ohne eine erzwungene Vereinheitlichung so aufgelöst werden, dass die Daten aus computerlinguistischer Sicht verwertbar sind.
Der Umgang mit der so entstandenen ›qualifizierten‹, nicht-deterministischen Datengrundlage seitens der Computerlinguistik ist zum aktuellen Zeitpunkt noch nicht definiert. Allerdings steht schon jetzt fest, dass auch in diesem Fall die Vorarbeit auf narratologischer Seite nicht ausreicht, um eine vorgefertigte Lösung anzuwenden. Im Bereich des Machine Learning werden nämlich widersprüchliche Daten als Problem betrachtet, das durch geeignete Filtermethoden gelöst wird – womit die widersprüchlichen Daten entfernt und nicht weiter berücksichtigt werden. Hier muss also ein neuer Umgang mit noisy data entwickelt werden. Geplant ist eine Parametrisierung der modellierten Konzepte, die auch die narratologischen Erkenntnisse zu impliziten Vorannahmen mit einschließt. Anschließend soll ein feedbackgesteuertes Machine Learning stattfinden, bei dem die Annotatoren die identifizierten Parameter einstellen. So können diese ins erarbeitete Modell integriert werden.
Dieses Vorgehen wird sich auch in der zu entwickelnden digitalen Heuristik für die CATMA-Umgebung niederschlagen: Dort sollen die automatischen Annotationsvorschläge von einer vorherigen Wahl bestimmter Grundannahmen durch den individuellen Nutzer und die individuelle Nutzerin abhängig sein. Dieses instant feedback-Konzept legt die methodischen Annahmen, die im Modul implementiert werden, zu einem großen Teil offen. Das Modul ist dadurch keine black box mehr, deren Funktionsweise und Methodik verborgen bleibt, und kann darüber hinaus von den Nutzern zur Überprüfung der eigenen narratologischen Vorannahmen – und der Konsistenz bei ihrer Anwendung – herangezogen werden.
Die beschriebenen Maßnahmen zum Umgang mit den sich aus interdisziplinärer Arbeit ergebenden Problemen führen also zu erstaunlich positiven Konsequenzen für die Einzelwissenschaften: Fachwissenschaftliche Dogmen werden durch den interdisziplinären Zugang fast schon notwendigerweise überdacht und theoretische bzw. praktische Unzulänglichkeiten ebenso behoben. Außerdem ergeben sich für die beiden Fachdisziplinen auch intradisziplinär positive Effekte. Das diesbezügliche Potential für den NLP-Zugang haben wir bereits skizziert. Im folgenden Abschnitt möchten wir nun beispielhaft einige Aspekte narratologischer Begriffsbildung ausführlicher vorstellen, die durch die interdisziplinäre Arbeit angeregt wurde.
3.4 Der Mehrwert für die Narratologie
Obwohl narratologische Kategorien gemeinhin als theoretisch durchdacht und leicht operationalisierbar gelten, zeigten sich bei ihrer formalisierten Anwendung im Rahmen manueller kollaborativer Annotation in heureCLÉA einige theoretische Unzulänglichkeiten. Typischerweise werden solche Unzulänglichkeiten, wie oben bereits angemerkt, entdeckt, wenn sich die Annotatoren hinsichtlich der korrekten narratologischen Bestimmung konkreter Textstellen nicht einig sind. In den Diskussionen über die Gründe für individuelle Annotations-Entscheidungen stellte sich oft die uneindeutige oder unvollständige Konzeption der jeweiligen narratologischen Kategorie als Ursache uneinheitlichen Markups heraus. Die festgestellten theoretischen Versäumnisse lassen sich in zwei Gruppen einteilen, die je unterschiedliche Problemlösungsstrategien erfordern:
(1) konzeptionelle Unvollständigkeiten, die leicht durch eine Vervollständigung der Kategorie mittels funktionaler Entscheidungen behoben werden können. Stellt sich bei der versuchten Anwendung einer Kategorie heraus, dass ihre Definition zu vage ist, um die Bestimmung einer fraglichen Textstelle vorzunehmen, müssen pragmatische Entscheidungen im Hinblick auf die Inklusion oder Exklusion bisher nicht bedachter textueller Oberflächenmerkmale getroffen werden.[45] Derartige Entscheidungen haben nur für die Anwendung der jeweiligen Kategorie Konsequenzen, nicht aber für weitere Konzepte;
(2) theoretische Unvollständigkeiten, die ihrerseits auf die unzureichende Bestimmung fundamentaler narratologischer Konzepte zurückzuführen sind. Probleme dieses Typs können nicht einfach durch pragmatische Entscheidungen behoben werden, weil die für eine Problemlösung notwendigen Setzungen auf der Ebene grundlegender narratologischer Konzepte weitreichende Konsequenzen für viele erzähltheoretische Einzelkategorien nach sich ziehen. Im Folgenden soll diese zweite Problemklasse anhand eines Beispiels erläutert werden:
In der Erzählung Der Tod von Thomas Mann ist bei dem Vergleich der Annotationsergebnisse im Hinblick auf die Geschwindigkeit der Erzählung[46] folgende Passage in den Fokus der Aufmerksamkeit gerückt (vgl. Abbildung 2):
»Ich habe die ganze Nacht hinausgeblickt, und mich dünkte, so müsse der Tod sein oder das Nach dem Tode: dort drüben und draußen ein unendliches, dumpf brausendes Dunkel. Wird dort ein Gedanke, eine Ahnung von mir fortleben und -weben und ewig auf das unbegreifliche Brausen horchen?«[47]
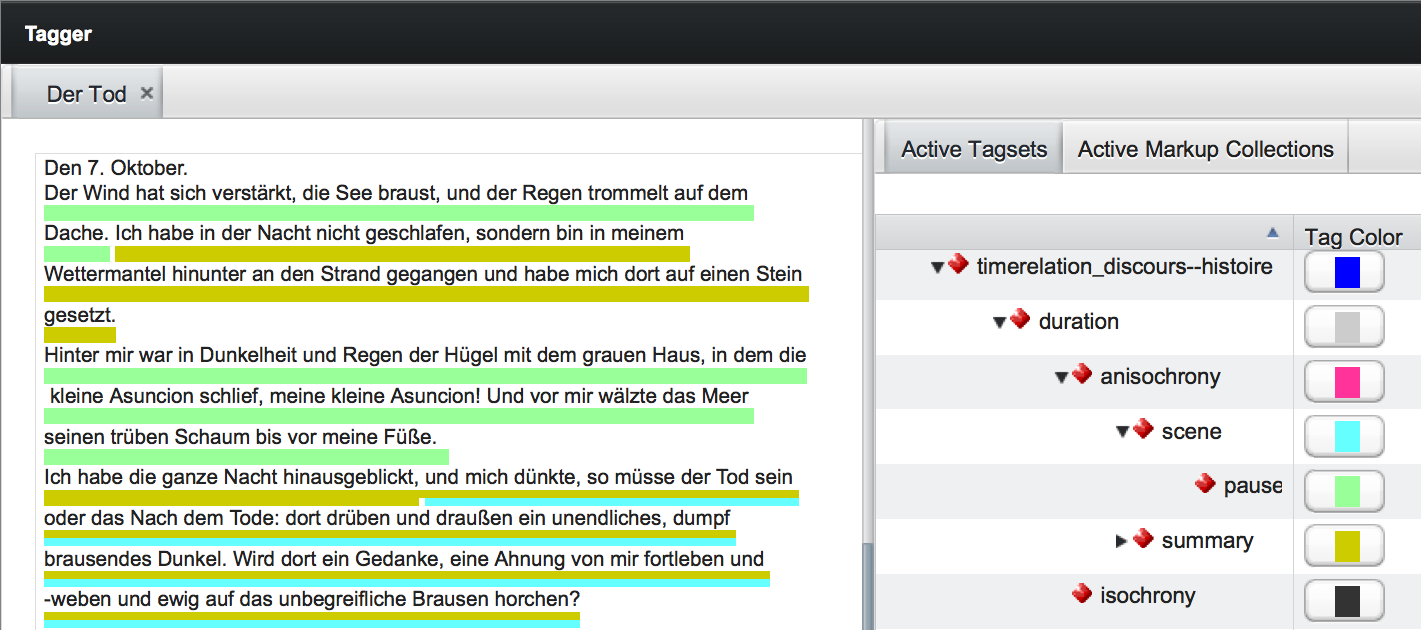
Die Passage nach dem ersten Komma (»und mich dünkte, so müsse…«) wurde von einigen Annotatoren als ›zeitraffend erzählt‹ eingeordnet, von anderen dagegen als ›zeitdehnendes Erzählen‹. Die Diskussion über die Gründe für die individuellen Entscheidungen hat gezeigt, dass die Annotatoren unterschiedliche Auffassungen darüber vertreten, was ein Ereignis ist. Betrachtet man mentale Vorgänge als Ereignisse, so muss man die zitierte Passage als zeitraffend klassifizieren, da die Gedanken des Erzählers in der fiktiven Welt vermutlich längere Zeit anhielten als die wenigen Sekunden, die in der Erzählung für ihre Wiedergabe eingeräumt werden. Ist man jedoch der Ansicht, dass es sich bei mentalen Prozessen nicht um Ereignisse handelt, so liegt in obiger Textstelle zeitdehnendes Erzählen vor: Der Bericht von Ereignissen wird verlangsamt durch die Darstellung nicht-ereignishafter Gegebenheiten. Die Frage danach, welche Konzeption von Ereignis korrekt oder sinnvoll ist, ist Gegenstand der Debatte um Narrativität: die für erzählende Texte konstitutive Eigenschaft, von Ereignissen zu berichten. Die unterschiedlichen Intuitionen der Annotatoren in Bezug auf die Definition von ›Ereignis‹ korreliert hier mit Schmids Konzeptionen von ›Ereignis I‹, das jegliche Form von Zustandsveränderung inkludiert, und ›Ereignis II‹, das zusätzliche Kriterien anführt, die Zustandsveränderungen aufweisen müssen, um als Ereignis zu gelten.[48] Wertet man Faktizität – also die Eigenschaft einer Zustandsveränderung, in der fiktiven Außenwelt einer Erzählung tatsächlich stattzufinden – als notwendige Eigenschaft von Ereignissen, muss die zitierte Passage aus Der Tod als Erzählpause klassifiziert werden.
Eine Entscheidung im Hinblick auf die ›richtige‹ Narrativitätsdefinition, die für die Lösung von Annotationsproblemen im Bereich der Erzählgeschwindigkeit notwendig wäre, hätte nun nicht nur für die fraglichen Kategorien Konsequenzen, sondern beispielsweise auch für die Bestimmung des Gegenstandsbereich der Narratologie und potenziell für eine Reihe weiterer Kategorien.[49]
Obwohl die theoretische Arbeit an narratologischen Grundkonzepten zu Beginn von heureCLÉA nicht geplant war, hat sich im Verlauf des Projekts, wie in Abschnitt 3.2 und 3.3 dargelegt, gezeigt, dass auch für diese komplexeren Theorieprobleme eine Lösung gefunden werden muss. Nur wenn bei widersprüchlichen Annotationen die jeweils zugrunde liegenden Basiskonzepte oder -annahmen offengelegt werden, sind die generierten Metadaten aus der NLP-Perspektive verwertbar. Aus diesem Grund arbeiten wir aktuell unter anderem an einer Analyse der literaturwissenschaftlichen Ereigniskonzeption(en), um eine Zuordnung diskrepanter Erzähldauer-Annotationen zu den verschiedenen Konzeptionen zu ermöglichen. Dieses Vorgehen ebnet den Weg für eine Parametrisierung der durch die digitale Heuristik generierten automatischen Annotationsvorschläge, wie sie in Abschnitt 3.3 bereits skizziert wurde.
4. Fazit
Das Zusammenspiel von Informatik und Hermeneutik, das das Projekt heureCLÉA auszeichnet, scheint also sowohl für das Projektziel der digitalen Heuristik als auch für die beteiligten Disziplinen selbst äußerst produktiv zu sein. Das Faszinierende daran ist das Wechselspiel zwischen interdisziplinärer und intradisziplinärer Arbeit: Beide Disziplinen bewegen sich aufeinander zu, um etwas Gemeinsames, eine Heuristik, schaffen zu können. Dies wird aber nicht dadurch erreicht, dass die angewendeten disziplinären Zugänge soweit aneinander angenähert werden, dass ein gemeinsamer interdisziplinärer Zugang entsteht. Vielmehr macht die Konfrontation mit den Methoden, Annahmen und Begriffen der jeweils anderen Disziplin eine Reflexion der eigenen disziplinären Methodologie nötig. Die in diesem Artikel dargestellten Problematiken sind nämlich durchweg spezifisch literaturwissenschaftlich oder spezifisch computerlinguistisch, und das, obwohl – oder gerade weil? – sie durch Rahmenbedingungen erzeugt werden, die wiederum exemplarisch für das Zusammenspiel von Informatik und Geisteswissenschaften sind. So wird etwa die Reproduzierbarkeit von Analyseergebnissen, die in heureCLÉA durch die noise-Problematik in der NLP relevant wurde, in den Geisteswissenschaften traditionell nicht thematisiert, da die Geisteswissenschaften meist mit dem wesentlich schwächeren Konzept der intersubjektiven Übereinstimmung operieren, ohne dieses weiter zu bestimmen. Die durch die Zusammenarbeit gewissermaßen erzwungene Auseinandersetzung mit der Reproduzierbarkeit von Analyseergebnissen kann aber, wie wir gezeigt haben, eine relevante Theorieentwicklung nach sich ziehen. Darüber hinaus hat sich die Reproduzierbarkeit von Analyseergebnissen als eine bislang wenig erforschte Gelingensbedingung für interdisziplinäre Projekte im Bereich der Digital Humanities herausgestellt. Für die Informatik bedeutet die Zusammenarbeit u.a., dass sie einen neuen Zugang zu bekannten Problemen entwickelt, der für hermeneutische – und nicht nur für mathematisch-formale Probleme – relevant ist.
Die bisherige und weiter geplante Arbeit in heureCLÉA ist also sowohl von entscheidender Bedeutung für das Gelingen des Projekts als auch ein Beitrag zu disziplinären Erkenntnissen oder methodologischen Weiterentwicklungen. Die Grundlage dafür liegt in den Rahmenbedingungen des Projekts bzw. in seinem Erkenntnisinteresse: Dadurch, dass die mit der digitalen Heuristik verbundenen Fragestellungen aus beiden beteiligten Feldern kommen, wird ein methodischer Mehrwert erzielt – der wiederum die Qualität der Ergebnisse steigert, da der Arbeit an der Fragestellung eine gemeinsame Auseinandersetzung mit den Gelingensbedingungen vorausgeht.
Die methodischen Konsequenzen echter interdisziplinärer Zusammenarbeit im Bereich der Digital Humanities bedeuten zwar zuerst einen Mehraufwand, der insbesondere durch die notwendig werdenden Übersetzungs- und Anpassungsleistungen zwischen den beteiligten Disziplinen bedingt ist. Wird diese Notwendigkeit aber erkannt und mit angemessener Sorgfältigkeit und unter Berücksichtigung der jeweiligen disziplinären Annahmen und Erkenntnisse in die Forschungsarbeit integriert, so wird offensichtlich, welche Schätze mit einem Digital Humanities-Zugang – sowohl disziplinär als auch interdisziplinär – zu bergen sind.
Fußnoten
-
[1]Vgl. für eine aktuelle Übersicht über die Definition von Digital Humanities z.B. Terras et al. 2013 und dort insbesondere das Kapitel IV.
-
[2]Diese Klassifizierung wurde auch im Rahmen der DHd-Konferenz im März 2014 in Passau mehrfach diskutiert, etwa von John Nerbonne in seiner Keynote Die Informatik als Geisteswissenschaft und von Eva Barlösius und Axel Philipps in ihrem Konferenzbeitrag Zur Sichtbarkeit von Street Art in Flickr. Methodische Reflexionen zur Zusammenarbeit von Soziologie und Informatik.
-
[3]Das Projekt heureCLÉA ist ein vom BMBF gefördertes eHumanities-Projekt, das von 02/2013–01/2016 an den Universitäten Hamburg und Heidelberg als Verbundprojekt durchgeführt wird (vgl. dazu auch Bögel et al.).
-
[4]
-
[5]Vgl. Genette 1972; Lahn / Meister 2013, S. 133–155.
-
[6]Vgl. zu den genutzten Analysekategorien die Beschreibung des heureCLÉA-Tagsets in den Annotationsguidelines Gius / Jacke 2014.
-
[7]Zu den regelbasierten Verfahren vgl. Strötgen / Gertz 2010.
-
[8]Damit ist heureCLÉA ein Beitrag zur computational narratology im Sinne von Mani, da es zu »exploration and testing of literary hypotheses through mining of narrative structure from corpora« (Mani 2013, unpag.) beiträgt.
-
[9]Bühler 2003, S. 3.
-
[10]Vgl. u.a. und grundlegend Schleiermacher 2012 sowie Dilthey 1990; für eine ›Philosophische Hermeneutik‹ vgl. Gadamer 1993.
-
[11]Bühler 2003, S. 5.
-
[12]Vgl. Bühler 2003, S. 13. Oft wird diese spezielle Struktur hermeneutischen Textverstehens als hermeneutischer Zirkel bezeichnet.
-
[13]Vgl. Kindt / Müller 2003 für einen Überblick.
-
[14]Auszuklammern sind hierbei jedoch intersubjektiv geteilte Vorannahmen wie allgemeines Weltwissen oder das Wissen über bestimmte literarische Konventionen – ohne diese im strengen Sinne extratextuellen Informationen kommt auch die narratologische Textanalyse oft nicht aus.
-
[15]Vgl. Kindt / Müller 2003, S. 294–295.
-
[16]Dass dem nicht so ist, illustriert die folgende Textstelle: »Dann ist sie, ohne ein Wort zu reden, bis zu meinem Schreibtisch gekommen und hat die Blumen vor mich hingelegt. Und in der nächsten Sekunde greift sie nach den verwelkten im grünen Glas. Mir war, als griffe man mir ins Herz« (Schnitzler: Blumen [1894], S. 106). Dass der Tempuswechsel vom Präteritum ins Präsens und zurück ins Präteritum hier keinen Zeitsprung darstellt, geht nicht zwingend aus dem Textmaterial hervor und ist deshalb kein deduktiver Schluss. Allerdings scheint es in diesem Fall vernünftig, inhaltliche Aspekte, die eine chronologische Abfolge anstatt eines doppelten Zeitsprungs indizieren, stärker zu gewichten als den Tempuswechsel. Der Zeitausdruck »in der nächsten Sekunde«, der den ersten und den zweiten Satz in zeitlich enge Relation setzt, sowie die Einschätzung der Reaktion des Erzählers als unmittelbar darauf folgend wären dann ausschlaggebend für die Bestimmung der Textstelle als ›chronologisch erzählt‹. Dieser Schluss stellt offensichtlich die beste Erklärung dar und erscheint unstrittig.
-
[17]Vgl. Kindt / Müller.
-
[18]Vgl. bspw. Kindt / Müller 2003, S. 299–301.
-
[19]Vgl. Jacke 2014, S. 129–130.
-
[20]Vgl. Kindt / Müller.
-
[21]Die Tatsache, dass XML inzwischen als de facto-Standard etabliert ist, widerspricht diesen Erkenntnissen. Bei XML handelt es sich um eingebettetes deklaratives Markup, das zwar aus technischer Sicht durchaus funktional ist, aber geisteswissenschaftlichen Methoden wie der hermeneutischen Textanalyse nicht gerecht werden kann (vgl. dazu auch Schmidt 2010).
-
[22]Vgl. Coombs et al. 1987. Diese Feststellung wird u.a. von Buzzetti und im bereits erwähnten Beitrag von Schmidt aufgegriffen (vgl. Buzzetti 2002, S. 63–64; Schmidt 2010, S. 338).
-
[23]Piez 2010, S. 202.
-
[24]Die flexible Gestaltung der Tagsets wird in CATMA durch die Nutzung des Feature Declaration System und der Feature Structures von TEI ermöglicht, wodurch das Markup gleichzeitig stand-off-Markup ist, das Überlappungen zulässt, und TEI-XML-kompatibel ist. Textbereiche (<seg>) sind mit Taginstanzen durch den Gebraucht von @ana-Attributen verlinkt, der Text selbst wird durch <ptr>-Elemente repräsentiert, die das originale Quelldokument referenzieren, welches unverändert belassen wird (vgl. weitere Informationen zur Implementierung von CATMA sowie Referenzen zu den genutzten Standards online).
-
[25]Der Grund für den flachen Ereignisbegriff in der NLP ist hauptsächlich darin zu suchen, dass er für das Testen von NLP-Systemen genutzt wird und dann für den jeweiligen Anwendungsfall konkretisiert wird. So geschieht es etwa alljährlich im Rahmen des SemEval-Workshops im Wettbewerb »Event extraction and classification« [vgl. 2015 online], bei dem sich verschiedene Systeme im automatischen Erkennen von Ereignissen messen. Da aber beide Disziplinen ihr Narrativitätskonzept maßgeblich auf Ereignissen aufbauen (vgl. bspw. Schmid 2008, S. 1–26, für den narratologischen Zugang sowie Chambers / Jurafsky 2008 für den NLP-Zugang), wäre es interessant zu untersuchen, inwiefern umfangreiche Analysen in der Narratologie ebenso eine gewisse Verflachung des Ereignisbegriffs nach sich ziehen würden. Diese Vermutung legt auch die Untersuchung in Gius 2013 nahe, in der die umfangreiche Anwendung narratologischer Kategorien nicht nur bislang unbeobachtete Interdependenzen zwischen den angewendeten Kategorien offenbart, sondern auch herausstellt, dass die Komplexität des narratologischen Theoriegebäudes zugunsten seiner Konsistenz verringert werden sollte (vgl. Gius 2015, S. 292–300 und S. 308–310).
-
[26]Vgl. Schmid 2008, S. 20–27. Zu Schmids Kriterien für ›Ereignis II‹ zählen neben Faktizität und Resultativität auch die Kriterien Relevanz, Unvorhersehbarkeit, Effekt, Irreversibilität und Nicht-Wiederholbarkeit.
-
[27]Vgl. Manning / Schütze 2001, S. 198–199.
-
[28]Vgl. Manning / Schütze 2001, S. 491.
-
[29]Jannidis et. al 2003, S. 3.
-
[30]Die menschliche Übereinstimmung wird also als obere Schranke für die automatischen Systeme verwendet, d.h., wenn Menschen nicht konsistent annotieren können, kann man das von einem automatischen System ebenfalls nicht erwarten.
-
[31]Non-deterministische Daten würden keine Vergleichbarkeit der Systeme ermöglichen. Deshalb strebt die NLP im Normalfall eindeutige und ›richtige‹ Lösungen an, gegen die dann etwa die im Rahmen der bereits erwähnten SemEval-Wettbewerbe antretenden Systeme evaluiert werden können.
-
[32]Vgl. für eine Analyse der Gründe der Polyvalenzthese Jannidis 2003.
-
[33]Vgl. Danneberg 1999, S. 101.
-
[34]Vgl. Kindt / Köppe 2008, S. 19; Fricke 1992, S. 216.
-
[35]Vgl. Jannidis 2006, S. 138–141; Jacke 2014, S. 126 und S. 130–131. Zur Methode des Schlusses auf die beste Erklärung vgl. die ausführliche Analyse von Lipton 1991.
-
[36]Vgl. das Beispiel zu Schnitzlers Blumen im Kommentarteil von Abschnitt 2.1.
-
[37]Vgl. Bögel et al. 2014, S. 951.
-
[38]Vgl. Mani / Schiffmann 2005.
-
[39]Für eine ausführlichere Beschreibung des Zugangs vgl. Bögel et al. 2014.
-
[40]Für eine Darstellung dieser Position vgl. Kindt / Müller 2003, S. 299–300.
-
[41]Vgl. die Erläuterung zum Schluss auf die beste Erklärung in Abschnitt 3.2.
-
[42]Føllesdal et al. 2008, S. 72.
-
[43]Vgl. dazu die Erläuterungen zur Definition der Prolepse in der Anmerkung zu Hebbels Matteo.
-
[44]Vgl. dazu die Erläuterungen zum Beispiel der Erzählgeschwindigkeit in Abschnitt 3.4.
-
[45]Ein derartiger Problemfall stellte sich an folgender Textstelle in Friedrich Hebbels Erzählung Matteo im Hinblick auf die Frage, ob es sich hier um eine Prolepse – bisher konzeptionalisiert als Vorgriff in der Zeit – handelt: »Sieh, morgen feire ich meine Hochzeit; zum Zeichen, daß du mir nicht mehr böse bist, kommst du auch, meine Mutter wird dich gern sehen.« (Hebbel: Matteo [1841], S. 466). Die Schwierigkeit ist hier dadurch gegeben, dass die angesprochene Figur am folgenden Tag nicht auf der Hochzeit erscheint. Um entscheiden zu können, ob hier eine Prolepse vorliegt, muss entschieden werden, ob dieses Konzept auch antizipierte Ereignisse fassen soll, die im Verlauf der Erzählung nicht eintreten.
-
[46]Unter ›Erzählgeschwindigkeit‹ versteht man in der Narratologie das Verhältnis zwischen der Menge an Ereignissen, von denen berichtet wird, und der Zeit, die für diesen Bericht notwendig ist.
-
[47]Mann: Der Tod [1897], S. 76.
-
[48]Vgl. die Erläuterungen zu ›Ereignis I‹ und ›Ereignis II‹ in Abschnitt 3.
-
[49]Eine ähnliche Verknüpfung von Annotationsproblemen und ungeklärten narratologischen Basiskonzepten findet sich bei der Annotation von Phänomenen der zeitlichen Ordnung einer Erzählung einerseits und dem grundlegenden narratologischen Konzept der Erzählebenen. Es kann nur sinnvoll das zeitliche Verhältnis von solchen Ereignissen bestimmt werden, die sich auf derselben Erzählebene befinden. Anhand welcher Faktoren ein Ebenenwechsel festzumachen ist, wird in der narratologischen Forschung noch diskutiert (vgl. Ryan 1991, S. 175–177; Pier 2013, unpag.).
Bibliographische Angaben
- Thomas Bögel / Michael Gertz / Evelyn Gius / Janina Jacke / Jan Christoph Meister / Marco Petris / Jannik Strötgen: Collaborative Text Annotation Meets Machine Learning. heureCLÉA, a Digital Heuristics of Narrative. In: DHCommons Journal 1 (2015) [online].
- Thomas Bögel / Jannik Strötgen / Michael Gertz: Computational Narratology. Extracting Tense Clusters from Narrative Texts, präsentiert auf der 9. Language Resources and Evaluation Conference (LREC ’14). Reykjavík 2014. [online]
- Axel Bühler: Grundprobleme der Hermeneutik. In: Hermeneutik. Basistexte zur Einführung in die wissenschaftstheoretischen Grundlagen von Verstehen und Interpretation. Hg. von Axel Bühler. Heidelberg 2003, S. 3–19. [Nachweis im GBV]
- Dino Buzzetti: Digital Representation and the Text Model. In: New Literary History 33 (2002), S. 61–88. DOI 10.1353/nlh.2002.0003.
- Nathanael Chambers / Dan Jurafsky: Unsupervised Learning of Narrative Schemas and Their Participants, präsentiert auf der Association for Computational Linguistics Konferenz (ACL 2009). Singapur 2009. [online]
- James H. Coombs / Allen H. Renear / Steven J. DeRose: Markup Systems and the Future of Scholarly Text Processing. In: Communications of the ACM 30 (1987), S. 933–947. DOI 10.1145/32206.32209.
- Lutz Danneberg: Zum Autorkonstrukt und zu einer methodologischen Konzeption der Autorintention. In: Rückkehr des Autors. Zur Erneuerung eines umstrittenen Begriffs. Hg. von Fotis Jannidis / Gerhard Lauer / Matías Martínez / Simone Winko. Tübingen 1999, S. 77–105. [Nachweis im OPAC]
- Defining Digital Humanities. A Reader. Hg. von Melissa Terras / Julianne Nyhan / Edward Vanhoutte. Farnham 2013. [Nachweis im OPAC]
- Wilhelm Dilthey: Die Entstehung der Hermeneutik [1900]. In: Wilhelm Dilthey: Gesammelte Schriften. Bd. 5. 8. Auflage. Stuttgart, Göttingen 1990, S. 317–338. [Nachweis im GBV]
- Dagfinn Føllesdal / Lars Walløe / Jan Elster: Die hypothetisch-deduktive Methode in der Literaturinterpretation. In: Moderne Interpretationstheorien. Ein Reader. Hg. von Tom Kindt / Tilmann Köppe. Göttingen 2008, S. 67–78. [Nachweis im GBV]
- Harald Fricke: Methoden? Prämissen? Argumentationsweisen. In: Vom Umgang mit Literatur und Literaturgeschichte. Positionen und Perspektiven nach der Theoriedebatte. Hg. von Lutz Danneberg / Friedrich Vollhardt. Stuttgart 1992, S. 211–227. [Nachweis im GBV]
- Hans-Georg Gadamer: Hermeneutik. Wahrheit und Methode [1960]. In: Hans-Georg Gadamer: Gesammelte Werke, Bd. 2. 2., durchgesehene Auflage. Tübingen 1993. [Nachweis im GBV]
- Gérard Genette: Discours du Récit. In: Gérard Genette: Figures III. Paris 1972, S. 67–282. [Nachweis im OPAC]
- Evelyn Gius: Erzählen über Konflikte: ein Beitrag zur digitalen Narratologie. Berlin, Boston 2015. [Nachweis im GBV]
- Evelyn Gius / Janina Jacke: Zur Annotation narratologischer Kategorien der Zeit. Guidelines zur Nutzung des CATMA-Tagsets. Hamburg 2014. [online]
- Friedrich Hebbel: Matteo [1841]. In: Werke. Hg. von Gerhard Fricke / Werner Keller / Karl Pörnbacher. Bd. 3. München 1963, S. 465–476. [online]
- Janina Jacke: Is There a Context-Free Way of Understanding Texts? The Case of Structuralist Narratology. In: Journal of Literary Theory 8 (2014), S. 118–139. [Nachweis im GBV]
- Fotis Jannidis: Polyvalenz – Konvention – Autonomie. In: Regeln der Bedeutung. Zur Theorie der Bedeutung literarischer Texte. Hg. von Fotis Jannidis / Gerhard Lauer / Matías Martínez / Simone Winko. Berlin 2003, S. 305–328. [Nachweis im GBV]
- Fotis Jannidis / Gerhard Lauer / Matías Martínez / Simone Winko: Der Bedeutungsbegriff in der Literaturwissenschaft. Eine historische und systematische Skizze. In: Regeln der Bedeutung. Zur Theorie der Bedeutung literarischer Texte. Hg. von Fotis Jannidis / Gerhard Lauer / Matías Martínez / Simone Winko. Berlin 2003, S. 3–30. [Nachweis im GBV]
- Fotis Jannidis: Analytische Hermeneutik. Eine vorläufige Skizze. In: Heuristiken der Literaturwissenschaft. Hg. von Uta Klein / Katja Mellmann / Steffanie Metzger. Paderborn 2006, S. 131–144. [Nachweis im GBV]
- Tom Kindt / Tilmann Köppe: Moderne Interpretationstheorien. Eine Einleitung. In: Moderne Interpretationstheorien. Ein Reader. Hg. von Tom Kindt / Tilmann Köppe. Göttingen 2008, S. 7–26. [Nachweis im GBV]
- Tom Kindt / Hans-Harald Müller: Wieviel Interpretation enthalten Beschreibungen? Überlegungen zu einer umstrittenen Unterscheidung am Beispiel der Narratologie. In: Regeln der Bedeutung. Zur Theorie der Bedeutung literarischer Texte. Hg. von Fotis Jannidis / Gerhard Lauer / Matías Martínez / Simone Winko. Berlin, New York 2003, S. 286–304. [Nachweis im GBV]
- Tom Kindt / Hans-Harald Müller: Zum Verhältnis von Deskription und Interpretation. Ein Bestimmungsvorschlag und ein Beispiel. In: Literatur interpretieren: interdisziplinäre Beiträge zur Theorie und Praxis. Hg. von Jan Borkowski / Stefan Descher / Felicitas Ferder / Philipp David Heine. Münster 2015. [online]
- Silke Lahn / Jan Christoph Meister: Einführung in die Erzähltextanalyse. Stuttgart, Weimar 2013. [Nachweis im OPAC]
- Peter Lipton: Inference to the Best Explanation. London, New York 1991. [Nachweis im GBV]
- Inderjeet Mani: Computational Narratology, in: the living handbook of narratology. Hg. von Peter Hühn / John Pier / Wolf Schmid / Jörg Schönert. Hamburg 2013. [online]
- Inderjeet Mani / Barry Schiffman: Temporally Anchoring and Ordering Events in News. In: Time and Event Recognition in Natural Language. Hg. von James Pustejovsky / Robert Gaizauskas. Amsterdam, Philadelphia 2005. [online]
- Thomas Mann: Der Tod. In: Thomas Mann: Große kommentierte Frankfurter Ausgabe. Werke – Briefe – Tagebücher. Hg. von Heinrich Detering. Bd. 2.1. Frankfurt/Main 2004, S. 71–78. [Nachweis im OPAC]
- Christopher D. Manning / Hinrich Schütze: Foundations of Statistical Natural Language Processing. 4. Auflage. Cambridge, Mass. 2001. [Nachweis im GBV]
- John Pier: Narrative Levels. In: the living handbook of narratology. Hg. von Peter Hühn / John Pier / Wolf Schmid / Jörg Schönert. Hamburg 2013. [online]
- Wendell Piez: Towards Hermeneutic Markup. An Architectural Outline. In: Digital Humanities 2010. Conference Abstracts, präsentiert auf der Digital Humanities Conference 2010 (DH 2010). London 2010, S. 202–205. [online]
- Marie-Laure Ryan: Possible Worlds, Artificial Intelligence, and Narrative Theory. Bloomington 1991. [Nachweis im GBV]
- Friedrich Schleiermacher: Vorlesungen zur Hermeneutik und Kritik [1805–1833]. In: Friedrich Schleiermacher. Kritische Gesamtausgabe. Bd. 4. Berlin [u.a.] 2012. [Nachweis im OPAC]
- Wolf Schmid: Elemente der Narratologie. Berlin [u.a.] 2008. [Nachweis im GBV]
- Desmond Schmidt: The Inadequacy of Embedded Markup for Cultural Heritage Texts. In: Literary and Linguistic Computing 25 (2010), S. 337–356. DOI 10.1093/llc/fqq007.
- Arthur Schnitzler: Blumen [1894]. In: Arthur Schnitzler: Ausgewählte Werke in acht Bänden. Bd. 1: Leutnant Gustl. Erzählungen 1892–1907. Frankfurt/Main 2004, S. 98–107. [Nachweis im GBV]
- Jannik Strötgen / Michael Gertz: HeidelTime. High Quality Rule-Based Extraction and Normalization of Temporal Expressions. In: Proceedings of the 5th International Workshop on Semantic Evaluation, präsentiert auf der Association for Computational Linguistics Conference. Uppsala 2010, S. 321–324. [online]