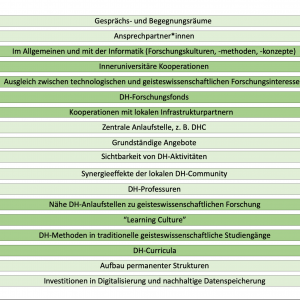
Im Mittelpunkt der Ausführungen steht die Betrachtung der Digital Humanities als community-induziertes Phänomen: Welche institutionellen Rahmenbedingungen brauchen die Digital Humanities, um Innovationspotenziale freizusetzen und eine tragende Rolle bezüglich der digitalen Transformation der Geisteswissenschaften einzunehmen?
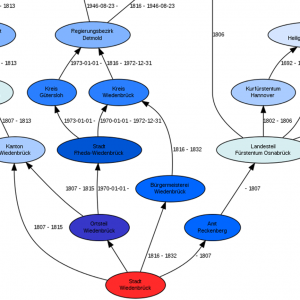
Im Beitrag wird ein Algorithmus beschrieben, der historische Urbanonyme automatisiert geokodiert und entsprechend ihrer historischen Verwaltungszugehörigkeit clustert.
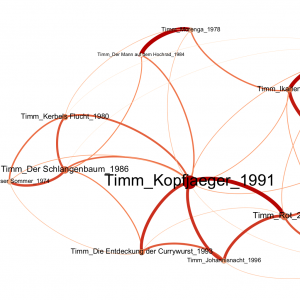
Eine hypothesengeleitete literaturwissenschaftliche Fallstudie mit der Anwendung von Digital-Humanities-Verfahren. Primärtexte der Analyse sind dreizehn längere Erzähltexte des deutschsprachigen Gegenwartsautors Uwe Timm.
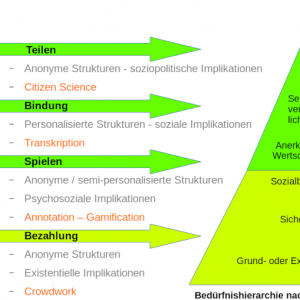
Der Artikel diskutiert kritisch den Begriff der ›Masse‹ unter der Perspektive von Crowdsourcing-Anwendungsfeldern. Es wird, auch unter historischer Rückbindung, ein Überblick zu spezifischen Methoden gegeben, die insbesondere im Feld der Citizen Science und in Projekten der Digital Humanities zum Einsatz kommen.
Der Beitrag entwirft und verfolgt mithilfe des Konzepts digitaler Experimentalsysteme eine epistemologische Perspektive auf digitale Zeitungssammlungen, die die Eigenarten, Effekte und Folgen digitaler Forschungskontexte für die Zeitungsforschung methodologisch hinterfragt.
Die vorliegende Studie präsentiert und erprobt eine Methodik, mit der die Paratexte eines mittelgroßen Textkorpus erfasst und analysiert werden. Zunächst wird eine Einführung in die Erzähltheorie gegeben, dann werden die einzelnen methodischen Schritte zur Erfassung der unterschiedlichen paratextuellen und textuellen Signale ausführlich dargelegt.
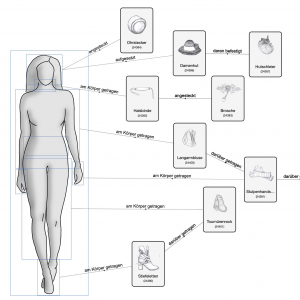
Der MUSE Datensatz stellt detaillierte, in eine umfassende Ontologie eingebettete Daten über Filmkostüme zur Verfügung, um Kostüme systematisch beschreibbar und analysierbar zu machen.
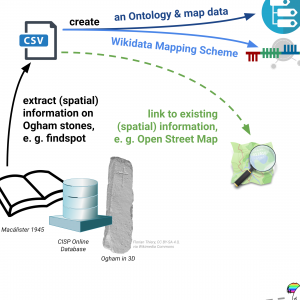
Die als ›Ogham‹-Steine bezeichneten Monolithen sind bereits umfassend verzeichnet worden. Die Informationen zu den einzelnen Steinen finden sich jedoch in verschiedensten analogen und Digitalen Quellen. Das vorgestellte Projekt bietet nun erstmals Link Open Data zu allen ›Ogham‹-Steinen und macht sie damit gemeinsam einheitlich untersuchbar.
Visual landscape especially in digital environments is not pre-given but is constructed in the very moment of watching. The authors therefore use methods of ›close playing‹ and ›digital walk-alongs‹ to analyse individual sense-making of players in a digital landscape.
Der Beitrag zeigt, wie die aus den Sozialwissenschaften stammenden ›Mixed Methods‹ in den Digital Humanities eingesetzt werden und welche Alternativen es hierzu gibt. Im Forschungsdesign der ›Entangled Methods werden Intraaktion, Datendiffraktion und Interferenzen als Kernkonzepte genutzt.